
Alok Menghrajani
Currently: security consulting and lecturer.
Previously: security engineering at Square Block. Co-author of Hack (the programming language) and put the 's' in https at Facebook Meta. Maker of various CTF puzzles.
This blog does not use any tracking cookies and does not serve any ads. Enjoy your anonymity; I have no idea who you are, where you came from, and where you are headed to. Keep the dream of an Internet from times past alive.
Home | Contact me | Github | RSS feed | Consulting services | Tools & games
Ever wondered what is Hacker News' favorite xkcd comic? Wonder no more! Here is how I answered this important question. (By favorite, I mean the most cited.)
Easy-peasy, just use BigQuery
There's a publicly available dataset on BigQuery — Google's big data analytics platform. From https://console.cloud.google.com/marketplace/product/y-combinator/hacker-news:
This dataset contains all stories and comments from Hacker News from its launch in 2006 to present. Each story contains a story ID, the author that made the post, when it was written, and the number of points the story received.
This public dataset is hosted in Google BigQuery and is included in BigQuery's 1TB/mo of free tier processing.[...]
Great, so we can grab the comments table and run some queries. Let's download all the comments which contains the string "xkcd" and process the data locally with ruby. The post-processing will probably be easier to implement in ruby than SQL, at least for me. We'll have to parse the free form text and extract comic IDs to find out which comic is the most cited — and hence most beloved by proxy.
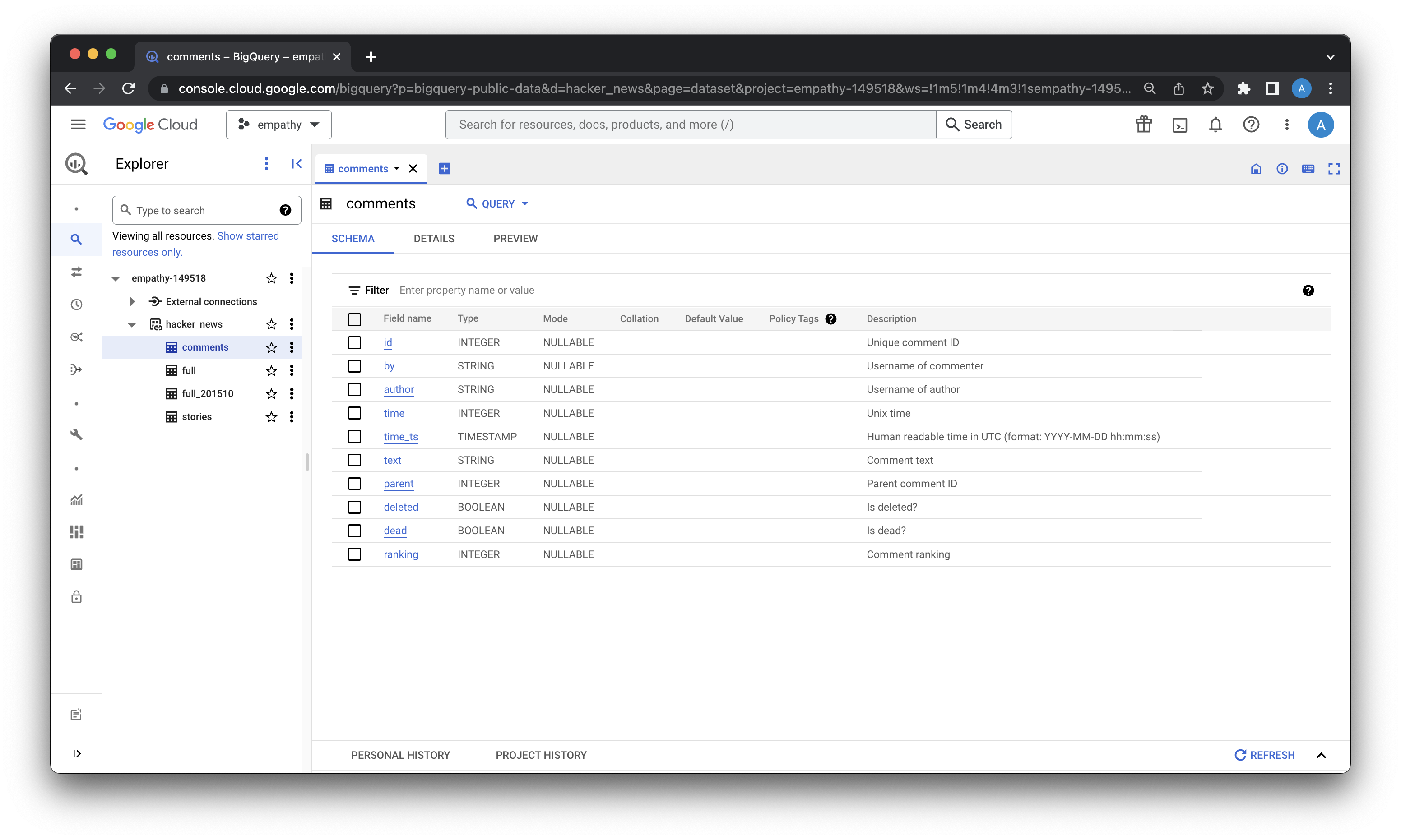
So I ran the following query:
SELECT
comments.id,
comments.by,
comments.author,
comments.text,
comments.time,
comments.deleted,
comments.dead,
comments.ranking
FROM
`bigquery-public-data.hacker_news.comments` AS comments
where UPPER(comments.text) LIKE '%XKCD%'
Since we are dealing with arbitrary text, it's better to download the result as JSONL vs CSV. I also rename the file to .jsonl, since the file isn't json and that's how my brain works.
$ mv bq-results-20221130-092554-1669800484644.json raw.jsonl
I then use some jq magic to count how many rows I have: $ cat raw.jsonl | jq -r '.id' | wc -l and get 6426.
Hmmm, something doesn't feel right. Let's grab the largest timestamp: cat raw.jsonl | jq -r '.time' | sort | tail -n 1
we get 1444704035, which we can convert to a human readable form: date -r 1444704035 and
get "Tue Oct 13 04:40:35 CEST 2015".
(yes I know, I'm doing cat pipe – For me, it's the right way to roll when quickly hacking on the command line. See also this comment).
I go back and check the details of the table I queried: it's stale. Womp womp.
Take two: use BigQuery with the correct table
The full table is what I want. It has all the posts and comments and is updated regularly.
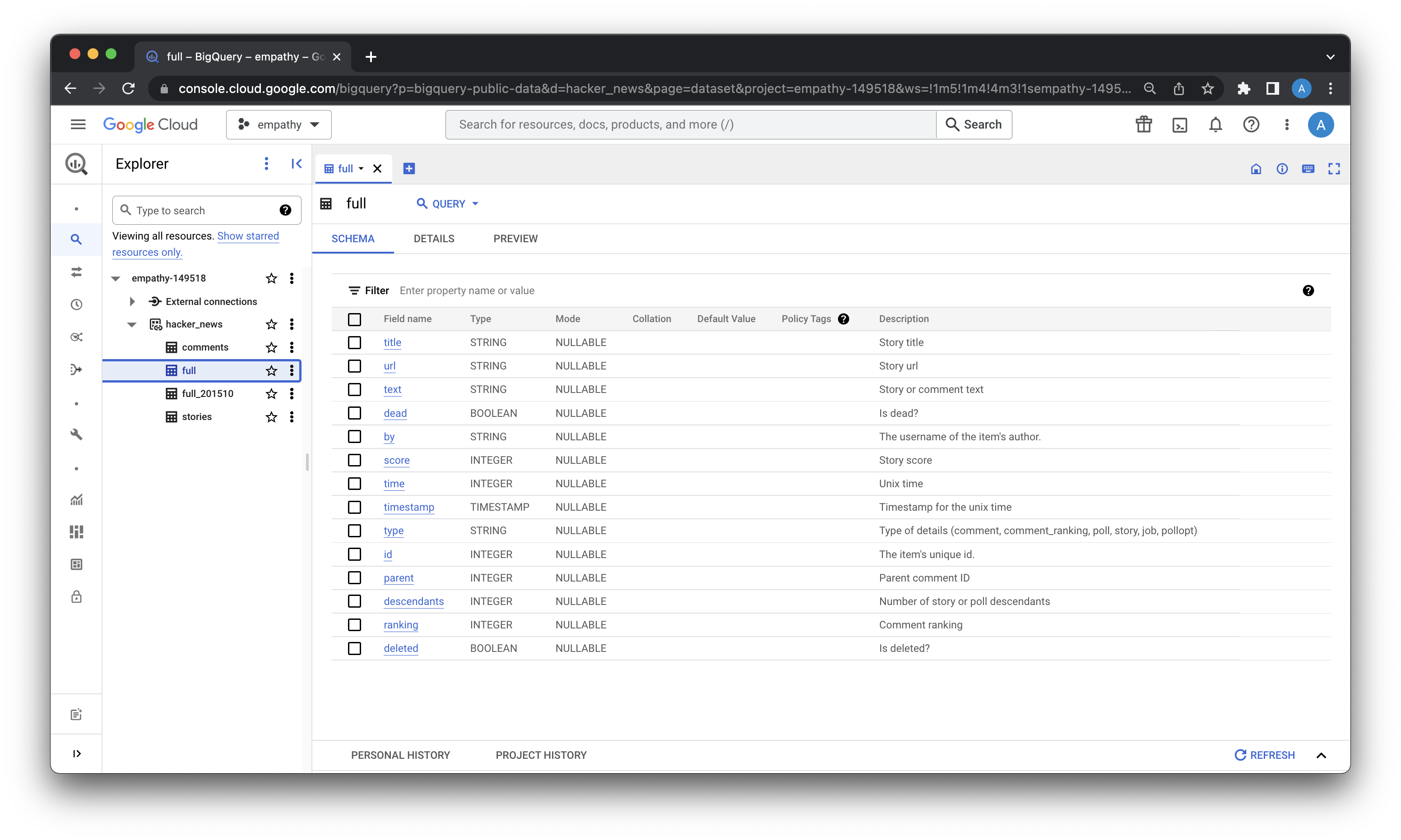
I craft a similar SQL query and 13 seconds later, I have what looks like the full dataset I need:
SELECT f.id, f.text, f.dead, f.by, f.time, f.ranking, f.deleted FROM `bigquery-public-data.hacker_news.full` AS f where UPPER(f.text) LIKE '%XKCD%' AND f.type="comment"
$ mv bq-results-20221130-093752-1669801126576.json raw.jsonl
$ cat raw.jsonl | jq -r '.id' | wc -l returns 18411. Compared
with hn.algolia.com's
19,524 results, we are roughly correct – unsure where the missing 1000 results
or so come from. Maybe algolia is fuzzy matching with some other string? Maybe
our dataset isn't complete?
Cleaning up the data
Our data needs a bit of cleaning up. If I run: $ cat raw.jsonl | jq -r '.text' | head -n 50 | grep --color "xkcd"
, I see results with a mix of html encoding a raw html:
<a href="http://xkcd.com/974/" rel="nofollow">http://xkcd.com/974/</a> <a href="https://xkcd.com/1235/" rel="nofollow">https://xkcd.com/1235/</a>
So I write a short ruby program to ingest the JSONL, unescape the html and save the result back as JSONL. I wish I could do this directly with jq, but I didn't find a way to do it.
I now need to deduplicate data. E.g. https://m.xkcd.com/2116/ is the same as http://www.xkcd.com/2116 and as http://xkcd.com/2116/. I also need to map imgs.xkcd.com links (e.g. https://imgs.xkcd.com/comics/python_environment.png) back to the comic IDs. In order to build the mapping of image files to IDs, I could crawl xkcd.com, use some kind of search API, manually map the files, etc. I opted for the xkcd's JSON endpoint:
$ mkdir imgs $ cd imgs $ for i in `seq 1 2700`; do curl -o $i.json https://xkcd.com/$i/info.0.json; done $ for i in `seq 1 2700`; do cat $i.json|jq -c >> ../xkcd.jsonl; done cat: 404.json: No such file or directory $ cd..
Fun fact: there's no comic 404!
Now I can write a ruby program (the last one?) which will extract comic IDs from the comments. I'll take m.xkcd.com into account but ignore other subdomains, such as blog.xkcd.com, what-if.xkcd.com, forums.xkcd.com (RIP), uni.xkcd.com, 3d.xkcd.com, etc.
Results
Top 10 most cited XKCD comics on Hacker News:
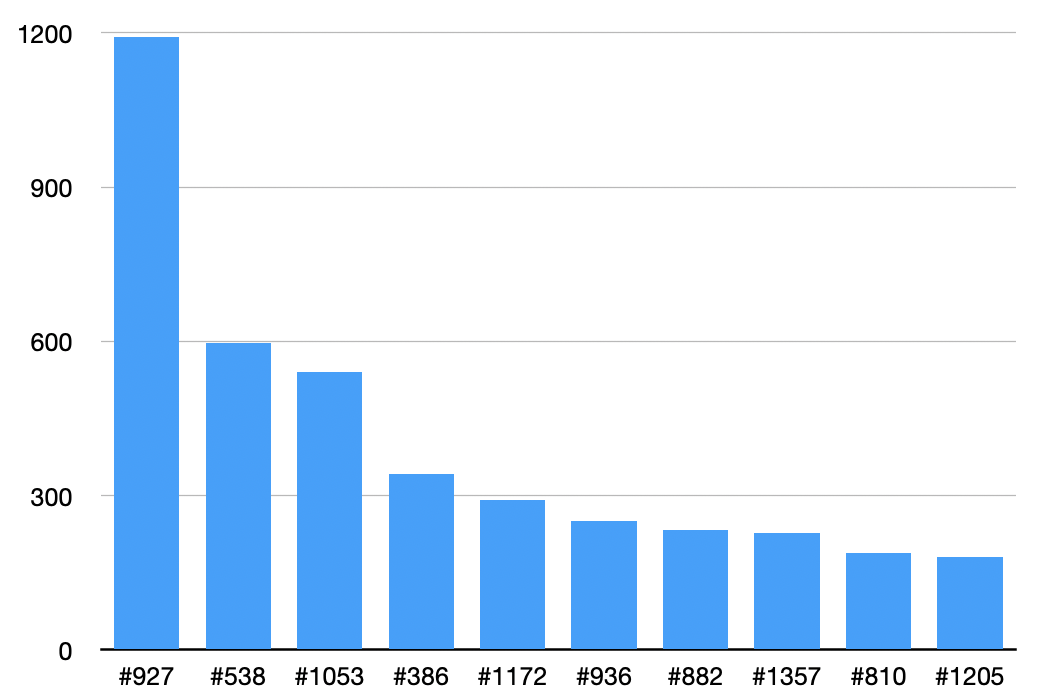
- Standards cited 1192 times.

- Security cited 596 times.

- Ten Thousand cited 540 times.

- Duty Calls cited 342 times.

- Workflow cited 291 times.

- Password Strength cited 251 times.

- Significant cited 233 times.

- Free Speech cited 228 times.

- Constructive cited 189 times.

- Is It Worth the Time? cited 180 times.

Other statistics
What happens if we look at the comic cited by the most number of different people? Pretty much the same result – top 7 are unchanged. 9th place gets replaced with Exploits of a Mom and the 8-10th places get switched around.
Person who cites the most XKCDs or person who cites the most different XKCDs? In both cases, it's TeMPOraL.
Caveats
Some images didn't get mapped back to their comic id. E.g. https://imgs.xkcd.com/comics/python_environment_2x.png which is a larger version of https://imgs.xkcd.com/comics/python_environment.png. Some comics, such as Time and Now have many images. I could manually map these but we are dealing with only a handful of entries. Ignoring these is fine.
In order to parse comments such as "xkcd 538 ($5 wrench) is also up there", I wrote some ugly regular expression. I'm probably failing to parse some IDs and also grabbing IDs incorrectly. That's inevitable when dealing with freeform text. The effect of parsing (or misparsing) on the top 10 is likely negligible: I tested by writing different regular expressions and the top 10 remained the same.
My personal favorites
Let's see how the top 10 compares with my personal favorites:
Compiling, Ten Thousand, Duty Calls, Standards, Exploits of a Mom, Estimation, Sandwich, YouTube, Nerd Sniping, Chess Coaster, TornadoGuard, Random Number, TED Talk, Supported Features, Success, Purity, Citogenesis, and Angular Momentum.I share a few common ones with the top 10. The main difference probably comes from me either liking less popular comics or some comics being easier to cite than others.
Raw data and code
You can access the raw jsonp files and my scrappy ruby code: https://github.com/alokmenghrajani/hackernews_xkcd_citations